안녕하세요. 항상 유익한 정보를 제공하기 위해 글을 쓰려고 노력하는 웹개발자입니다!
오늘은 Prisma에서 aggregate와 groupby를 사용해보려 해요
프로젝트에 적용할 통계 데이터를 합산하는 로직에서 컬럼을 합산해야하는 로직이 필요하여 알아보게 됐어요!
딱 2가지! 1차 relation, 2차 relation 두가지를 prisma에선 어떻게 구할 수 있는지 알아봅시다
Aggregate 사용법
prisma 문서를 보시면 aggregate는 number field에서만 사용할 수 있다고 나와있습니다!
즉, 다음과 같은 option들을 이용해 통계를 구할 수 있어요.
| options | description |
| where | 말그대로 SQL의 WHERE 절 |
| _count | 조건에 맞는 개수를 리턴 |
| _avg | 조건에 맞는 데이터의 평균 |
| _sum | 조건에 맞는 데이터의 합산 |
| _min | 조건에 맞는 데이터 중 최소 |
| _max | 조건에 맞는 데이터 중 최대 |
Aggregate 적용
그러면 본격적으로 사용법을 알아보도록 할게요! 1차 관계에서의 sum 먼저 구현해보도록 할게요!
먼저 prisma.[schema명].aggregate를 통해 작성하고, _sum 옵션을 사용해보세요!
const questionData = await prisma?.questionData.aggregate({
_sum: {
joinCnt: true, // sum을 하고 싶은 컬럼명을 true설정
},
});
// Schema Model
model QuestionData {
questionDataId Int @id @default(autoincrement()) @map("question_data_id")
correctCnt Int @default(0) @map("correct_cnt")
wrongCnt Int @default(0) @map("wrong_cnt")
joinCnt Int @default(0) @map("join_cnt")
@@map("question_data")
}
위와 같이 원하는 옵션을 사용 후, 적용하고 싶은 컬럼을 true로 놓는다면 joinCnt의 총합을 구하는 sum이 됩니다!

위의 사진과 같이 _sum에 총합이 나오는 것을 볼 수 있어요.
같은 원리를 통해 _avg, _count, _min 등도 구해볼게요



위의 결과들을 합쳐보면 count 30870개에서 sum이 7031이니 avg는 0.2278이 계산되어 나오죠!
2차 Relation Aggregate
사실 제가 sum을 구하려했던 목적은 2차 관계에서 prisma는 어떻게 sum을 하는지였습니다!
groupby 로는 prisma에서 2차 관계 sum을 구하기가 어렵....더라구요!
저의 관계는 Subject -> Question -> QuestionData 의 연관관계는 아래 모델에서 확인할 수 있어요!
subjectId를 통해 QuestionData의 sum을 구해야하는 로직입니다!
model Subject {
subjectId Int @id @default(autoincrement()) @map("subject_id")
subjectName String @unique @map("subject_name") @db.VarChar(20)
questions Question[]
@@map("subject")
}
model Question {
questionId Int @id @default(autoincrement()) @map("question_id")
subjectId Int @map("subject_id")
subject Subject? @relation(fields: [subjectId], references: [subjectId])
questionData QuestionData?
@@map("question")
}
model QuestionData {
questionDataId Int @id @default(autoincrement()) @map("question_data_id")
question Question? @relation(fields: [questionId], references: [questionId])
questionId Int @unique @map("question_id")
correctCnt Int @default(0) @map("correct_cnt")
wrongCnt Int @default(0) @map("wrong_cnt")
joinCnt Int @default(0) @map("join_cnt")
bookmarkCnt Int @default(0) @map("bookmark_cnt")
@@map("question_data")
}
SQL로 짜려면 쪼인..하고... GROUP BY 하고... WHERE 하고... SUM 해서 나와야하지만...!
역시 prisma 너무 간단하게 where절에서 questionData와 연관된 question의 subjectId가 동일한 데이터를 조회하여 _sum 옵션만 사용하면 끝나게 됩니다!
const questionData = await prisma?.questionData.aggregate({
where: {
question: {
subjectId: Number(subjectId), //
},
},
_sum: {
joinCnt: true,
wrongCnt: true,
correctCnt: true,
},
});
결과도 깔끔하게 나오게 되었습니다!

Prisma vs MySQL 속도 비교
그렇다면 과연 단순 Count, Sum 등이 얼마나 속도차이가 날지 좀 궁금하네요.
총 데이터는 30870개와 12만개의 데이터 2가지로 비교해보도록 하지요ㅎㅎ
먼저 count 쿼리로 30870개인 경우의 MySQL 입니다.
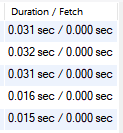
다음은 Prisma 입니다.

흠 .. 눈에 띄는 정도는 아니지만 prisma가 확실히 조금 느린 경향이 있네요! (고작 3만개입니다..^^)
그러면 다음으로는 12만개로 해보도록 할게요!


흐으음 ... 평균적으로는 prisma가 느려보이네요!
두번째는 sum을 해보도록 할께요!
12만개로만 진행했는데 생각보다 별차이가 없었습니다!
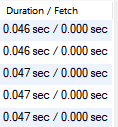
이정도 데이터에서는 속도를 따질게 없다는게 보여지네요.... 천만건정도에서 다음에 다시 테스트를 해보도록 할게요.. ㅎㅎㅎ 무의미한 실험이지만, 저의 프로젝트 경우에선 가볍게 prisma로 작업하는게 너무 편하다는걸 알아버렸어요!
이상으로 오늘의 내용은 마치고 또 다시 공부하는 내용이 생기면 찾아오도록 할게요~!
'DB' 카테고리의 다른 글
| [Prisma] sum 구하기 - groupby 사용법 (0) | 2023.11.28 |
|---|